Redis is enterprise, or advanced, key-value store with optional persistence. There are couple of reasons why everyone loves Redis. Why I do?
Following command can install redis server on ubuntu. That's all.
apt-get install redis-server
2. It's incredible fast. Look at following tables. One million remote operations per second.
3. It supports large set of commands. More than some kind of database, it's rather enterprise remote-aware hash-map, hash-set, sorted-list or pub/sub channel solution supporting TTL or Lua script environment among others. See all commands.
4. It's optimized to use low computer resources, cpu and ram. Despite the redis server is single thread app it can achieve such great performance.
I've already started to talk about purposes at the beginning. We have primarily targeted two points. First, we can use Redis within super-fast deployment of our app when latency matters.
Secondly, I wanted to compare in-memory and persistent stores. Does it really worth to think about such in-memory solution?
Setup
I used following setup:
- Redis server 2.2.6: HP Proliant BL460c gen 8, 32core 2.6 GHZ, 192GB RAM, ubuntu 12 server
- Tests executor: xeon, 16 cores, 32gb ram, w8k server
- 10Gbps network
- jedis java client
- kryo binary serialization
As Redis cluster feature was in development in the time of measuring these numbers, I used only one machine. 32 cores were really overestimated as Redis used one plus one core indeed.
Performance Measurement of Redis
Batch Size
As main memory is touched only, it's all about network transmission. It's almost same for all sizes of batches.
Variable Connections
Utilizing LPUSH again to append to different number of keys. Every keys is accessed using different connection.
Ohhh. One million inserted messages per second to one Redis instance. Incredible. Java client uses NIO so this is the answer why it somehow scales with much more tcp connections. Increasing number of network pipes where a client can push the data enables better throughput.
Occupied Memory
Blob within a list.
There is some build-in compression which appeared within large message test.
Long Running
The goal of this test is to fill the main memory (192GB) with one redis instance to find out if there are some scalability limitations.
Redis fill the main memory with blob messages till OOM. The shape of this progress within the time is almost flat.
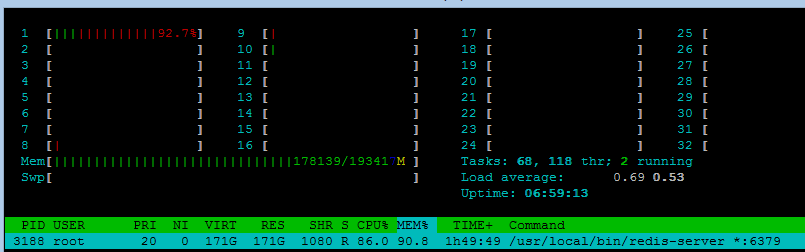
Persistence
Redis forks a new thread for I/O. Numbers are almost same if the data are persisted within one second frames. TPS goes significantly down when Redis writes every updated key to the drive but this mode ensures best durability.
Large Messages
How the performance is affected when message size increases to tens of mbytes?
Conclusion
The numbers are impressive. One-thread app successfully process almost one million of small messages in memory.
Redis performance is incredible. We could expect certain limitations because of one-threaded design which causes "serializable" behavior. Maybe this lockless implementation is the reason why redis server can handle such great throughput.
Redis performance is incredible. We could expect certain limitations because of one-threaded design which causes "serializable" behavior. Maybe this lockless implementation is the reason why redis server can handle such great throughput.
On the other hand, the right comparison against other competitors uses redis persistence feature. The performance is much more worse. Three times. Well, the persistence requirement can be the decision maker.
I've already mentioned great command set. You can probably model almost any behavior. Even if Redis primarily targets caches, there are commands allowing to calculate various stats, hold unique sets etc. The script made from these commands is powerful and very fast.
Everything is always about performance and features. Redis has both of them :-)
I've already mentioned great command set. You can probably model almost any behavior. Even if Redis primarily targets caches, there are commands allowing to calculate various stats, hold unique sets etc. The script made from these commands is powerful and very fast.
Everything is always about performance and features. Redis has both of them :-)
0 comments:
Post a Comment